An often forgotten formula for the mean of a random variable 
=\sum_{x=0}^{\infty} \Big(1-F(x)\Big)")
And for the continous case:
=\int_{x=0}^{\infty} \Big(1-F(x)\Big)")
This blog post is going to illustrate how these formulas arise.
more →An often forgotten formula for the mean of a random variable
And for the continous case:
This blog post is going to illustrate how these formulas arise.
more →Those of you who already have tested for the variance of data from a normal distribution may have asked themselves how the link between normal variance and chi-squared distribution arises. Trust me: The story, which I will tell you, is an exciting one! more →
Today we have an interesting experiment. Let’s take a huge load of data on NYSE share performance, do some filtering and forward the result into Gephi. Take a look below for some pretaste.
 Knowing which shares tend to move with each other can be valuable information in your market analysis. It’s up to you whether you want to learn about Stock Data Downloader / Gephi first or whether you want to get your insights straightaway – here we go. more →
Knowing which shares tend to move with each other can be valuable information in your market analysis. It’s up to you whether you want to learn about Stock Data Downloader / Gephi first or whether you want to get your insights straightaway – here we go. more →
One of the more interesting applications of statistics is the analysis of stock quotation data. A solid analysis can give you an advantage when deciding which shares to buy. Also you can search for patterns; which shares move together with others..? However, the first step is collecting all the data which are required – and this is a cumbersome task!

Let’s download historical stock, trust and index quotations for analysis purposes
I found lots of discussions in various forums, on StackOverflow and so on. But nobody provided a solution for downloading a bulk of data at once. As a consequence, I created my own solution (which you can download here) based on the Google Finance API.

In office, we have some really slow software application. In order to show that the waiting times over the whole departement incredibly sum up and lead to high costs, I needed an objective measurement method. First, I got a manual stopwatch which allowed to track how long I had waited. However, I was not able to answer the question: “How long do I work with this program in office routine?” There are not so many tools out there and most of them were a little bit over the top. That is why I developed a small utility for monitoring software usage over time: Software Usage Recorder! more →
Fossil fuels will vanish in the future – for sure! What we don’t know is the exact point in time when this is going to happen. Based on the BP Statistical Review of World Energy 2016, we find that fossil fuels will last up to 100 years. Proven oil reserves, which will last for the next 50 years, are expected. However, BP has an interest in keeping the energy reserve numbers great: Any other message would make the oil price jump up and renewable energy would become less unattractive. Especially when considering the rising demand for energy (e. g. in China) we need to prepare for earlier shortages. But what does it take to substitute fossil energy sources by renewable ones?

World energy consumption in 2014 mainly adopted from the simplified energy balance sheet table of the IEA; an asterisk (*) indicates that the data was not fine-grained enough to guarantee full accuracy [1][2]
Not only do the numbers reflect an incredible thirst for energy, but it also shows to which extent we damage earth by exploiting these resources. The bottom line is that this energy supply from coal, oil, natural gas and nuclear energy (~107,000 TWh) must be substituted. What are the options?
References
| ↑1 | “Key world energy statistics”. International Energy Agency. |
| ↑2 | “Nuclear power in the world today”. World Nuclear Association. |
I like white sneakers and I don’t want them to become dirty. That’s why I always check on the next day’s precipitation probability. If I intend to leave only for a couple hours, then the breakdown of the rain risk is of particular interest to me. When comparing the probabilities on hourly and daily basis I could rarely figure out the relationship between both. Consider the following weather forecast:
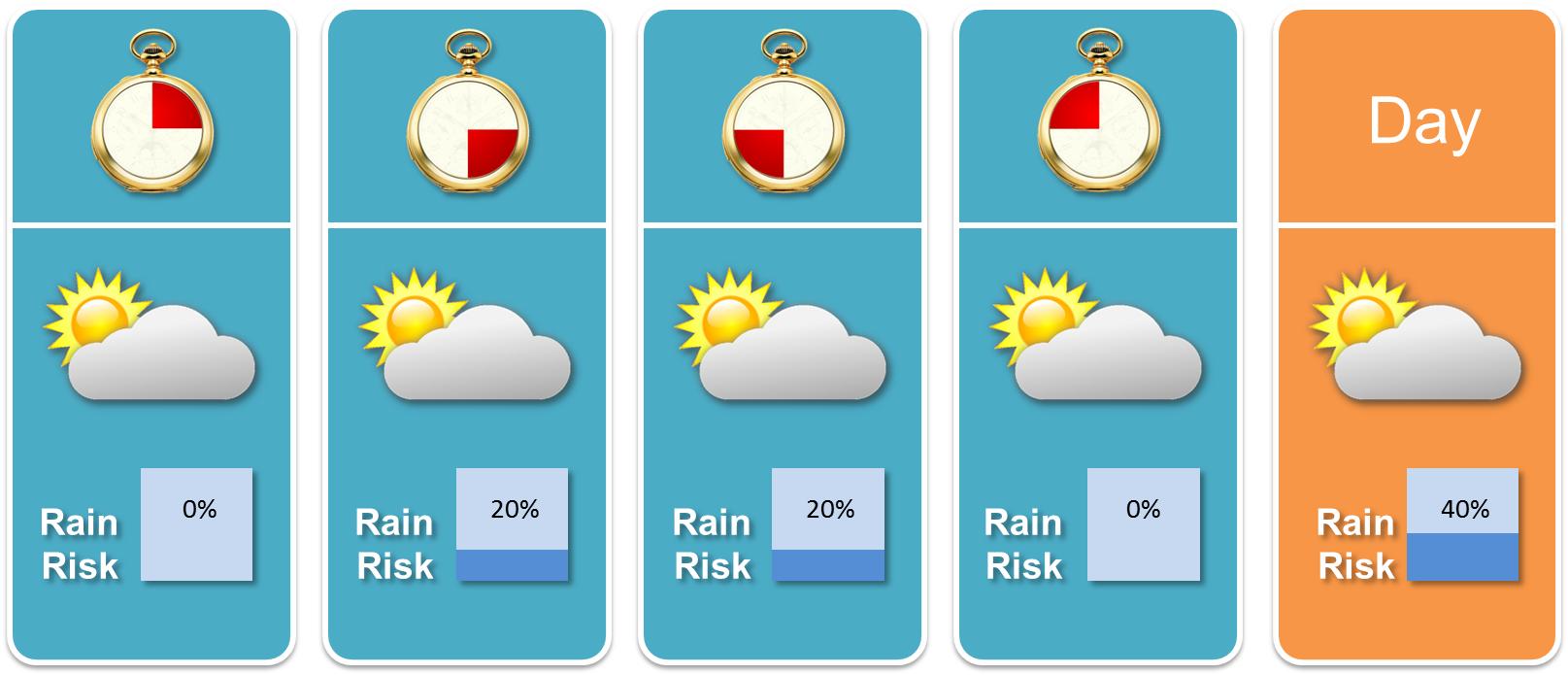
Fictional weather forecast on daily and 6-hours basis
For simplicity I chose to present the rain risk for periods of 6 hours length. Anyway, in what way are the daily rain risk of 40% and its breakdown of 20% over 12 hours related? Can we trust the weather forecast’s statements anyway? This article will discuss the topic.
Those of you who have read previous articles of mine already know that I like tricky questions – especially if they don’t look too complicated in the first place. Here’s one for you to try: Does the penny make a half or a full rotation when rolling it around another penny?

Would you expect Mr Lincoln to show his head upside down?



© 2026 Insight Things
Theme by Anders Noren — Up ↑