Those of you who already have tested for the variance of data from a normal distribution may have asked themselves how the link between normal variance and chi-squared distribution arises. Trust me: The story, which I will tell you, is an exciting one! more →
Insight Things
A scientific blog revealing the hidden links which shape our world
Tag: explanation
I guess that you already know a little bit about hypothesis testing. For instance, you might have carried out tests in which you tried to reject the hypothesis that your sample comes from a population with a hypthesized mean µ. As you know that the sample mean follows a t-distribution (or the normal distribution in case of huge samples), you can define a rejection region based on a specific significance level α. In a one-sided test, sample means which are less than a critical value CV might be considered to be rather unlikely. If the obtained sample’s mean falls into this region, the hypothesis gets rejected at this particular signficance level α.
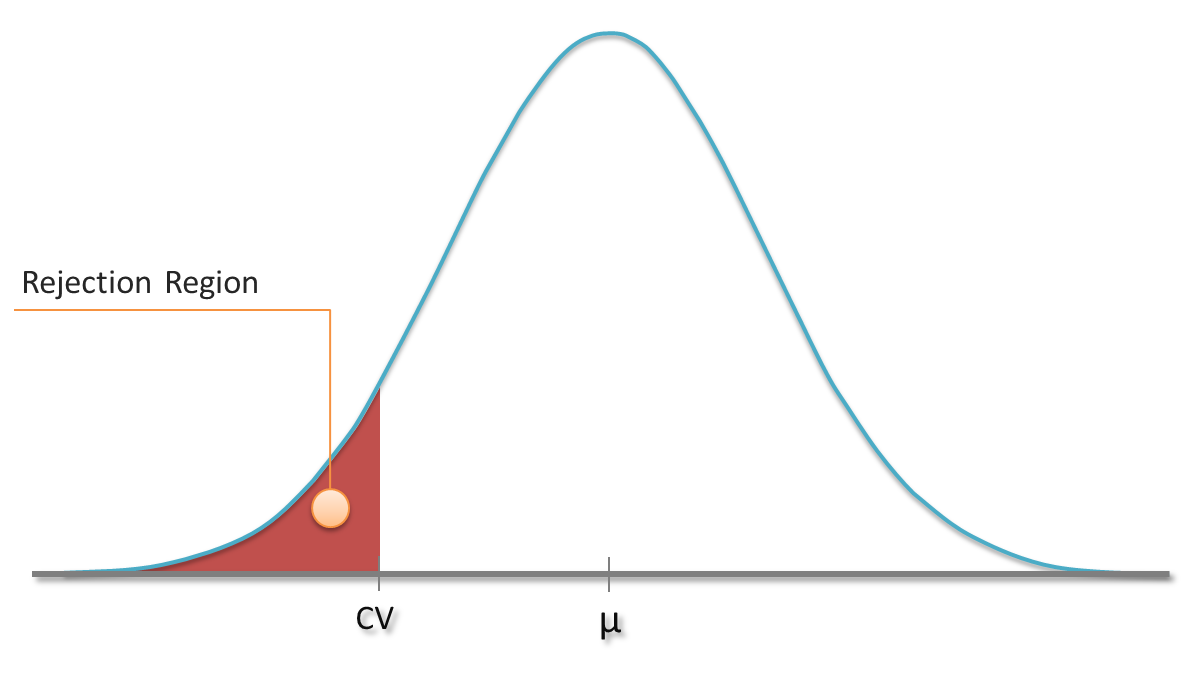
Distribution of sample mean and rejection region for one-sided test
We know the chance of rejecting the hypothesis although it’s true (Type I error), because it is the chance of obtaining just one of those values from the rejection region (plotted red). But how likely are we to reject a hypothesis if it’s indeed false? In other words: How small is the type II error? more →
One of statistic’s foundations lies in the fact you can add variances. Maybe you wonder a little bit, because the formula for the variance does not look like that at first glance. This article will show you the proof why and under which circumstances adding variances is a valid practice. Please check the information given in my articles on addition and multiplication of expected values, if you do not have collected experiences with it yet. more →
I’ve already explained in a demonstrative way how the formula for sum squared numbers arises. Not only will I only show in this article how to calculate simple series like 1+2+3+4+…., but you will also see how we enhance our findings to tackle more complicated series like 1³+2³+3³+…. These formulas are applied in many different contexts. more →
Have you ever wondered how the formula for the sum of squares (1+4+9+16+25+…) arises? Then this article is for you! We will see that there is a geometric interpretation for the problem of adding squared numbers. This interpretation will lead to the well-known formula (see “Sum of Squares, Cubes and Higher Powers” for higher powers). Curious? Then don’t let us waste time but start! more →



© 2026 Insight Things
Theme by Anders Noren — Up ↑