I guess that you already know a little bit about hypothesis testing. For instance, you might have carried out tests in which you tried to reject the hypothesis that your sample comes from a population with a hypthesized mean µ. As you know that the sample mean follows a t-distribution (or the normal distribution in case of huge samples), you can define a rejection region based on a specific significance level α. In a one-sided test, sample means which are less than a critical value CV might be considered to be rather unlikely. If the obtained sample’s mean falls into this region, the hypothesis gets rejected at this particular signficance level α.
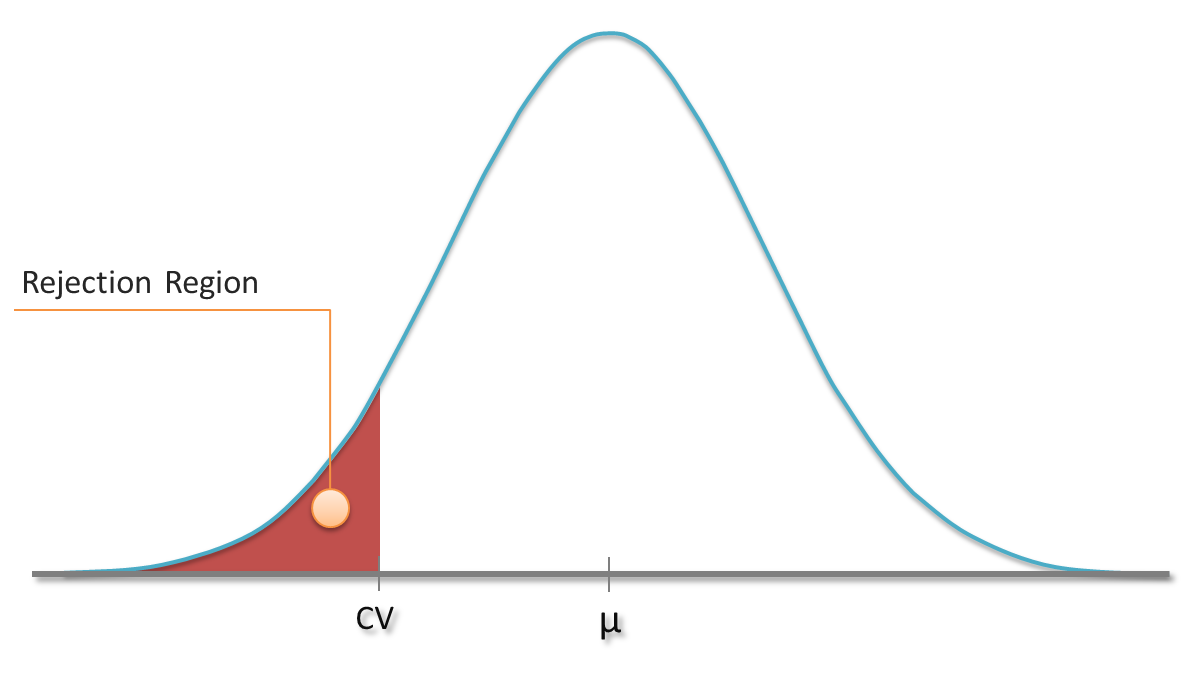
Distribution of sample mean and rejection region for one-sided test
We know the chance of rejecting the hypothesis although it’s true (Type I error), because it is the chance of obtaining just one of those values from the rejection region (plotted red). But how likely are we to reject a hypothesis if it’s indeed false? In other words: How small is the type II error? more →


